




 mẫu cho việc học AI")
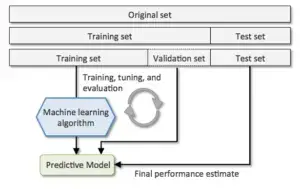
Trong AI, trong quá trình huấn luyện 1 mô hình (model) thì chúng ta phải có 1 tập dữ liệu (dataset) đển đánh giá được mô hình (đánh giá thuật toán được đào tạo có tốt không và tốt như thế nào).
Có 3 loại dataset, dựa vào mục đích mà người ta phân loại:
Bộ dữ liệu huấn luyện – training set
Bộ xác thực – Validation set
Bộ dữ liệu thử nghiệm – testing set
Trong quá trình học AI, ví dụ như mình cần phát hiện 1 hình có chữ viết tay các con số từ 0 đến 9, thì mình phải huấn luyện mô hình của mình từ 1 tập dự liệu CÓ SẲN khoảng 5000 6000 hình rồi. Hình dưới là 1 hình ví dụ trong tập dữ liệu có sẳn đặt tên là MNIST, hình số 4 bên trái:

còn hình số 4 bên phải 1 ví dụ về kết quả của mô hình mà họ đã huấn luyện sẳn. Còn theo 1 thuật toán khác (các xây dựng mô hình với thuật toán và thông số khác nhau), thì đây là kết quả ví dụ:
Các bạn có thể thấy được output của mô hình với số 4 ở trên. Nghĩa là, khi input là 1 hình mà mắt thường có thể biết được là số 4, nhưng với mô hình trên đưa ra nhận định là tỉ lệ số 4 là 70%, số 9 là 20% chẳng hạn.
Đây là 1 ví dụ về dataset về phân loại 10 đối tượng như trong hình:

và 1 ví dụ về kết quả huấn luyện với dataset này (dataset tên là CIFAR10; có dataset CIFAR100 dành cho huấn luận 100 đối tượng; chắc cũng trăm ngàn hình).

Khác với ví dụ về output của mô hình phát hiện các số viết tay từ 0 đến 9 như đầu bài, vì thực tế viết từ 0 đến 9 rất đơn giản, còn việc các hình chụp cho 10 đối tượng trong CIFAR10 là đa dạng hơn nhiều. Ví dụ, hình con ngựa có thể đầu bên trái hoặc đầu bên phải hình (trong khi trong dữ liệu MNIST thì số 9 thì phải viết theo 1 cách đó thôi chứ không lật ngược được).
Tóm lại, trong quá trình học AI và có những tập dự liệu có sẳn mà cộng đồng đã đóng góp trong suốt thời gian dài, thì đây là 1 trong số các nguồn mà bạn có thể download tập dữ liệu mẫu có sẳn và tập với việc coding cho mô hình của mình:
- Kaggle
Mấy ví dụ trên là dataset tên là MNIST (cho chữ viết tay từ 0 đến 9), CIFAR10 (vài trăm nghìn hình về 10 đối tượng). Papers with Code
UCI Machine Learning Repository
Registry of Open Data on AWS
Google Dataset Search
Microsoft Datasets
Reddit datasets
CMU Libraries
Public Datasets trên Github
- YouTube Dataset
Thứ tự các nguồn trên là mình theo trên mạng, chắc là dựa vào mức độ thông dụng, hoặc dựa vào số lượng dataset. Mình chỉ liệt kê tên như là keyword và các bạn tự search nó có gì nhé.

{kind=link}